Introduction to Sentence Transformers
The Sentence Transformers library is a powerful tool for generating sentence embeddings using transformer models. This blog post focuses on the Transformer-based Denoising AutoEncoder (TSDAE), a cutting-edge model designed for unsupervised learning of sentence embeddings. With its ability to capture semantic meaning effectively, TSDAE is a game-changer in natural language processing.
What is TSDAE?
The TSDAE model encodes damaged sentences into fixed-sized vectors, requiring the decoder to reconstruct the original sentences from these embeddings. This process ensures that the semantics are well captured, leading to high-quality sentence embeddings.
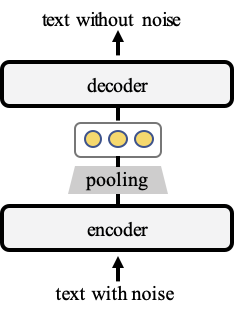
Main Features of TSDAE
- Unsupervised Learning: Train models without labeled data.
- High-Quality Embeddings: Generate embeddings that capture semantic meaning effectively.
- Flexible Training: Supports various datasets and configurations.
- Easy Integration: Compatible with existing Sentence Transformers models.
How to Set Up TSDAE
Setting up TSDAE is straightforward. Follow these steps to get started:
from sentence_transformers import SentenceTransformer, LoggingHandler
from sentence_transformers import models, util, datasets, evaluation, losses
from torch.utils.data import DataLoader
# Define your sentence transformer model using CLS pooling
model_name = "bert-base-uncased"
word_embedding_model = models.Transformer(model_name)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(), "cls")
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
# Define a list with sentences (1k - 100k sentences)
train_sentences = [
"Your set of sentences",
"Model will automatically add the noise",
"And re-construct it",
"You should provide at least 1k sentences",
]
# Create the special denoising dataset that adds noise on-the-fly
train_dataset = datasets.DenoisingAutoEncoderDataset(train_sentences)
# DataLoader to batch your data
train_dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True)
# Use the denoising auto-encoder loss
train_loss = losses.DenoisingAutoEncoderLoss(
model, decoder_name_or_path=model_name, tie_encoder_decoder=True
)
# Call the fit method
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=1,
weight_decay=0,
scheduler="constantlr",
optimizer_params={"lr": 3e-5},
show_progress_bar=True,
)
model.save("output/tsdae-model")
Using TSDAE with a Sentences File
To train TSDAE using sentences from a file, use the train_tsdae_from_file.py script. Ensure that each line in the text file contains one sentence. The model will automatically handle the training process.
Training on the AskUbuntu Dataset
The AskUbuntu dataset is a manually annotated dataset for the AskUbuntu forum. TSDAE can be trained on this dataset using the train_askubuntu_tsdae.py script. The model achieves impressive MAP scores, outperforming many pretrained models.
| Model | MAP-Score on test set |
|---|---|
| TSDAE (bert-base-uncased) | 59.4 |
| pretrained SentenceTransformer models | |
| nli-bert-base | 50.7 |
| paraphrase-distilroberta-base-v1 | 54.8 |
| stsb-roberta-large | 54.6 |
TSDAE as a Pre-Training Task
TSDAE serves as a powerful pre-training method, outperforming traditional Mask Language Model (MLM) tasks. After training with TSDAE loss, you can fine-tune your model like any other SentenceTransformer model.
Community and Contributions
The Sentence Transformers community is vibrant and welcoming. Contributions are encouraged, and you can participate by submitting issues, pull requests, or engaging in discussions. Check the GitHub repository for more details.
License Information
The project is licensed under the Apache License 2.0. This allows for free use, reproduction, and distribution of the software, provided that the terms of the license are followed.
Conclusion
In conclusion, the TSDAE model within the Sentence Transformers library offers a robust solution for unsupervised sentence embedding learning. Its ability to generate high-quality embeddings makes it a valuable tool for developers and researchers alike. For more information, visit the GitHub repository.
FAQ
What is TSDAE?
TSDAE stands for Transformer-based Denoising AutoEncoder, a model designed for unsupervised learning of sentence embeddings.
How do I train a TSDAE model?
You can train a TSDAE model using a list of sentences or from a text file containing one sentence per line. The training process is straightforward and well-documented.
What datasets can I use with TSDAE?
TSDAE can be trained on various datasets, including the AskUbuntu dataset, which is specifically designed for question-answering tasks.
Is TSDAE open-source?
Yes, TSDAE is part of the Sentence Transformers library, which is open-source and available under the Apache License 2.0.